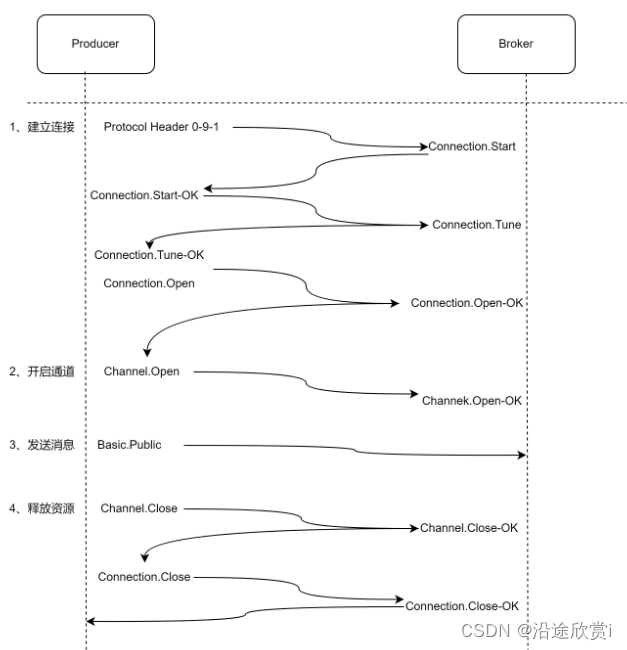
1、AMQP 协议
1.1、AMQP 生产者的流转过程
当客户端与Broker 建立连接的时候,会调用factory .newConnection 方法,这个方法会进一步封装成Protocol Header 0-9-1 的报文头发送给Broker ,以此通知Broker 本次交互采用的是AMQPO-9-1 协议,紧接着Broker 返回Connection.Start 来建立连接,在连接的过程中涉及Connection.Start/.Start-OK 、Connection.Tune/.Tune-Ok , Connection.Open/ .Open-Ok 这6 个命令的交互。
当客户端调用connection .createChannel 方法准备开启信道的时候,其包装Channel . Open 命令发送给Broker ,等待Channel.Open-Ok 命令。当客户端发送消息的时候,需要调用channel . basicPublish 方法,对应的AQMP 命令为Basic.Publish ,注意这个命令和前面涉及的命令略有不同,这个命令还包含了Content Header 和Content Body 。 Content Header 里面包含的是消息体的属性,例如,投递模式、优先级等,而Content Body 包含消息体本身。
当客户端发送完消息需要关闭资源时,涉及Channel.Close/.Close-Ok 与Connection.Close/.Close-Ok 的命令交互。
1.2、消费者的流转过程

消费者客户端同样需要与Broker 建立连接,与生产者客户端一样,协议交互同样涉及
Connection.Start/ . Start-Ok 、Connection.Tune/.Tune-Ok 和Connection.Open/ . Open-Ok 等。
紧接着也少不了在Connection 之上建立Channe l,和生产者客户端一样,协议涉及Channel . Open/Open-Oko 如果在消费之前调用了channel . basicQos(int prefetchCount) 的方法来设置消费
者客户端最大能"保持"的未确认的消息数,那么协议流转会涉及Basic.Qos/.Qos-Ok 这两个AMQP 命令。
在真正消费之前,消费者客户端需要向Broker 发送Basic.Consume 命令(即调用channel.basicConsume 方法〉将Channel 置为接收模式,之后Broker 回执Basic . Consume - Ok 以告诉消费者客户端准备好消费消息。紧接着Broker 向消费者客户端推送(Push) 消息,即Basic.Deliver 命令,有意思的是这个和Basic.Publish 命令一样会携带Content Header 和Content Body。
消费者接收到消息并正确消费之后,向Broker 发送确认,即Basic.Ack 命令。在消费者停止消费的时候,主动关闭连接,这点和生产者一样,涉及Channel . Close/ . Close-Ok 手口Connection.Close/ . Close-Ok 。
1.3、关于 AMQP 命令对照
| 名称 | 是否包含内容体 | 对应客户端的方法 | 简要描述 |
|---|---|---|---|
| Connection.Start | 否 | factory.newConnection | 建立连接相关 |
| Connection.Start-OK | 否 | 同上 | 同上 |
| Connection.Tune | 否 | 同上 | 同上 |
| Connection.Tune-OK | 否 | 同上 | 同上 |
| Connection.Open | 否 | 同上 | 同上 |
| Connection.Open-OK | 否 | 同上 | 同上 |
| Connection.Close | 否 | connection.close | 关闭连接 |
| Connection.Close-OK | 否 | 同上 | 同上 |
| Channel.Open | 否 | connection.openChannel | 开启信道 |
| Channel.Open-OK | 否 | 同上 | 同上 |
| Channel.Close | 否 | channel.close | 关闭信道 |
| Channel.Close-OK | 否 | 同上 | 同上 |
| Exchange.Declare | 否 | channel.exchangeDeclare | 声明交换器 |
| Exchange.Declare-OK | 否 | 同上 | 同上 |
| Exchange.Delete | 否 | channel.exchangeDelete | 删除交换器 |
| Exchange.Delete-OK | 否 | 同上 | 同上 |
| Exchange.Bind | 否 | channel.exchangeBind | 交换器与交换器绑定 |
| Exchange.Bind-OK | 否 | 同上 | 同上 |
| Exchange.Unbind | 否 | channel.exchangeUnbind | 交换器与交换器解绑 |
| Exchange.Unbind-OK | 否 | 同上 | 同上 |
| Queue.Declare | 否 | channel.queueDeclare | 声明队列 |
| Queue.Declare-OK | 否 | 同上 | 同上 |
| Queue.Bind | 否 | channel.queueBind | 队列与交换器绑定 |
| Queue.Bind-OK | 否 | 同上 | 同上 |
| Queue.Purge | 否 | channel.queuePurge | 清除队列中的内容 |
| Queue.Purge-OK | 否 | 同上 | 同上 |
| Queue.Delete | 否 | channel.queueDelete | 删除队列 |
| Queue.Delete-OK | 否 | 同上 | 同上 |
| Queue.Unbind | 否 | channel.queueUnbind | 队列与交换器解绑 |
| Queue.Unbind-OK | 否 | 同上 | 同上 |
| Basic.Qos | 否 | channel.basicQos | 设置未被确认消费的个数 |
| Basic.Qos-OK | 否 | 同上 | 同上 |
| Basic.Consume | 否 | channel.basicConsume | 消费消息(推模式) |
| Basic.Consume-OK | 否 | 同上 | 同上 |
| Basic.Cancel | 否 | channel.basicCancel | 取消 |
| Basic.Cancel-OK | 否 | 同上 | 同上 |
| Basic.Publish | 是 | channel.basicPublish | 发送消息 |
| Basic.Return | 是 | 无 | 未能成功路由的消息返回 |
| Basic.Deliver | 是 | 无 | Broker 推送消息 |
| Basic.Get | 否 | channel.basicGet | 消费消息(拉模式) |
| Basic.Get-OK | 否 | 同上 | 同上 |
| Basic.Ack | 否 | channel.basicAck | 确认 |
| Basic.Reject | 否 | channel.basicReject | 拒绝(单条拒绝) |
| Basic.Recover | 否 | channel.basicRecover | 请求Broker重新发送未被确认的消息 |
| Basic.Recover-OK | 否 | 同上 | 同上 |
| Basic.Nack | 否 | channel.basicNack | 拒绝(可批量拒绝) |
| Tx.Select | 否 | channel.txSelect | 开启事务 |
| Tx.Select-OK | 否 | 同上 | 同上 |
| Tx.Commit | 否 | channel.txCommit | 事务提交 |
| Tx.Commit-OK | 否 | 同上 | 同上 |
| Tx.Rollback | 否 | channel.txRollback | 事务回滚 |
| Tx.Rollback-OK | 否 | 同上 | 同上 |
| Confirm.Select | 否 | channel.confirmSelect | 开启发送确认模式 |
| Confirm.Select-OK | 否 | 同上 | 同上 |
2、客户端开发指南
2.1、连接RabbitMQ
连接方式有两种,一种是通过参数化方式连接;另一种是通过URI方式连接。如下示例代码:
//方式一
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername(USERNAME);
factory.setPassword(PASSWORD);
factory.setVirtualHost(virtualHost) ;
factory.setHost(IP_ADDRESS);
factory.setPort(PORT) ;
Connection conn = factory.newConnection();//方式二
ConnectionFactory factory = new ConnectionFactory();
factory.setUri("amqp://userName:password@ipAddress:portNumber/virtualHost");
Connection conn = factory.newConnection();
//Connection 接口被用来创建一个Channel:
Channel channel = conn.createChannel();注意事项:Connection 可以用来创建多个Channel 实例,但是Channel 实例不能在线程问共享,应用程序应该为每一个线程开辟一个Channel 。某些情况下Channel 的操作可以并发运行,但是在其他情况下会导致在网络上出现错误的通信帧交错,同时也会影响友送方确认( publisher confrrm)机制的运行,所以多线程问共享Channel 实例是非线程安全的。
Channel 或者Connection 中有个isOpen 方法可以用来检测其是否己处于开启状态(关于Channel 或者Connectio 的状态可以参考2.6 节)。但并不推荐在生产环境的代码上使用 isOpen 方法,这个方法的返回值依赖于shutdownCause (参考下面的代码)的存在,有可能会产生竞争,如下代码所示:
public boolean isOpen() {synchronized(this.monitor) (return this.shutdownCause == null;}
}//错误使用示例
public void brokenMethod(Channel channel) {if (channel.isOpen()) {// The following code depends on the chan口el being in opeηstate .// However there is a possibility of the change in the channel state// between isOpen() and basicQos(l) call//………………channel.basicQos(1);}
}通常情况下,在调用 createXXX 或者 newXXX 方法之后,我们可以简单地认为Connection 或者Channel 已经成功地处于开启状态,而并不会在代码中使用isOpen 这个检测方法。如果在使用Channel 的时候其己经处于关闭状态,那么程序会抛出一个com.rabbitmq . client.ShutdownSignalException ,我们只需捕获这个异常即可。当然同时也要试着捕获IOExceptio口或者SocketException ,以防Connection 意外关闭。如下代码所示:
public void validMethod(Channel channel) {try (//………………channel.basicQos(l);} catch (ShutdownSignalException sse) {// poss 工bly check if channel was closed// by the time we started action and reasons for// closing it//………………}catch (IOException ioe) {// check why connection was closed}
}2.2、关于 exchangeDeclare 方法详解
exchangeDeclare 有多个重载方法,这些重载方法都是由下面这个方法中缺省的某些参数构成的。
Exchange.DeclareOk exchangeDeclare(String exchange,String type,boolean durable,boolean autoDelete, boolean internal,Map<String, Object> arguments) throws IOException ;这个方法的返回值是Exchange.DeclareOK, 用来标识成功声明了一个交换器。各个参数详细说明如下所示:
- exchange : 交换器的名称。
- type : 交换器的类型,常见的如fanout、direct 、topic、headers
- durable: 设置是否持久化。durable 设置为true 表示持久化, 反之是非持久化。持久化可以将交换器存盘,在服务器重启的时候不会丢失相关信息。
- autoDelete : 设置是否自动删除。autoDelete 设置为true 则表示自动删除。自动删除的前提是至少有一个队列或者交换器与这个交换器绑定, 之后所有与这个交换器绑定的队列或者交换器都与此解绑。注意不能错误地把这个参数理解为: "当与此交换器连接的客户端都断开时, RabbitMQ 会自动删除本交换器" 。
- internal : 设置是否是内置的。如果设置为true ,则表示是内置的交换器,客户端程序无法直接发送消息到这个交换器中,只能通过交换器路由到交换器这种方式。
- argument : 其他一些结构化参数,比如alternate- exchange
2.3、关于 queueDeclare 方法详解
queueDeclare 相对于exchangeDeclare 方法而言,重载方法的个数就少很多, 它只有两个重载方法:
Queue.DeclareOk queueDec1are() throws IOException;Queue.DeclareOk queueDeclare (String queue, boolean durable, boolean exclusive,
boolean autoDelete, Map<String , Object> arguments) throws IOException;不带任何参数的queueDeclare 方法默认创建一个由RabbitMQ 命名的(类似这种amq.gen-LhQzlgv3GhDOv8PIDabOXA 名称,这种队列也称之为匿名队列〉、排他的、自动删除的、非持久化的队列。方法的参数详细说明如下所述:
- queue : 队列的名称。
- durable: 设置是否持久化。为true 则设置队列为持久化。持久化的队列会存盘,在服务器重启的时候可以保证不丢失相关信息。
- exclusive : 设置是否排他。为true 则设置队列为排他的。如果一个队列被声明为排他队列,该队列仅对首次声明它的连接可见,并在连接断开时自动删除。这里需要注意三点:排他队列是基于连接( Connection) 可见的,同一个连接的不同信道(Channel)是可以同时访问同一连接创建的排他队列; "首次"是指如果一个连接己经声明了一个排他队列,其他连接是不允许建立同名的排他队列的,这个与普通队列不同:即使该队列是持久化的,一旦连接关闭或者客户端退出,该排他队列都会被自动删除,这种队列适用于一个客户端同时发送和读取消息的应用场景。
- autoDelete: 设置是否自动删除。为true 则设置队列为自动删除。自动删除的前提是:至少有一个消费者连接到这个队列,之后所有与这个队列连接的消费者都断开时,才会自动删除。不能把这个参数错误地理解为: "当连接到此队列的所有客户端断开时,这个队列自动删除",因为生产者客户端创建这个队列,或者没有消费者客户端与这个队列连接时,都不会自动删除这个队列。
- argurnents: 设置队列的其他一些参数,如x-rnessage-ttl 、x-expires 、x -rnax-length 、x-rnax-length-bytes 、x-dead-letter-exchange 、x-deadletter-routing-key, x-rnax-priority 等。
特别注意:生产者和消费者都能够使用queueDeclare 来声明一个队列,但是如果消费者在同一个信道上订阅了另一个队列,就无法再声明队列了。必须先取消订阅,然后将信道直为"传输"模式,之后才能声明队列。
2.4、关于消息消费
RabbitMQ 的消费模式分两种: 推( Push )模式和拉( Pull )模式。推模式采用Basic.Consume进行消费,而拉模式则是调用Basic.Get 进行消费。
2.4.1、推模式
在推模式中,可以通过持续订阅的方式来消费消息,使用到的相关类有:
import com.rabbitmq.client.Consumer;
import com.rabbitmq.client.DefaultConsumer;接收消息一般通过实现Consumer 接口或者继承DefaultConsumer 类来实现。当调用与Consumer 相关的API 方法时, 不同的订阅采用不同的消费者标签(consumerTag) 来区分彼此,在同一个Channel 中的消费者也需要通过唯一的消费者标签以作区分, 关键消费代码如下所示:
boolean autoAck = false;
channel.basicQos(64);
channel.basicConsume(queueName, autoAck, "myConsumerTag",new DefaultConsumer(channel) {@Overridepublic void handleDelivery(String consumerTag,Envelope envelope,AMQP.BasicProperties properties ,byte[] body) throws IOException {String routingKey = envelope.getRoutingKey();String contentType = properties.getContentType() ;long deliveryTag = envelope.getDeliveryTag() ;// (process the message components here . .. )channel.basicAck(deliveryTag, false);}
});注意, 上面代码中显式地设置autoAck 为false , 然后在接收到消息之后进行显式ack 操作(channel.basicAck ), 对于消费者来说这个设置是非常必要的,可以防止消息不必要地丢失。此外Channel 类中basicConsume 方法有如下几种形式:
String basicConsume(String queue , Consumer callback) throws IOException ;String basicConsume(String queue , boolean autoAck, Consumer callback) throws
IOException;String basicConsume(String queue , boolean autoAck, Map<String, Object>
arguments , Consumer callback) throws IOException ;String basicConsume(String queue , bool ean autoAck, String consumerTag,
Consumer callback) throws IOException ;String basicConsume(String queue , boolean autoAck, String consumerTag,
boolean noLocal , boolean exclusive, Map<String , Object> arguments , Consumer callback)
throws IOException ;对应的参数说明如下所示:
- queue : 队列的名称:
- autoAck : 设置是否自动确认。建议设成false ,即不自动确认:
- consumerTag: 消费者标签,用来区分多个消费者:
- noLocal : 设置为true 则表示不能将同一个Connectio 中生产者发送的消息传送给这个Connection 中的消费者:
- exclusive : 设置是否排他:
- arguments : 设置消费者的其他参数:
- callback : 设置消费者的回调函数。用来处理RabbitMQ 推送过来的消息,比如DefaultConsumer,使用时需要客户端重写(override) 其中的方法。
对于消费者客户端来说重写handleDelivery 方法是十分方便的。更复杂的消费者客户端会重写更多的方法, 具体如下:
void handleConsumeOk(String consumerTag);void handleCancelOk(String consumerTag);void handleCancel(String consumerTag) throws IOException;void handleShutdownSignal(String consumerTag , ShutdownSignalException sig);void handleRecoverOk(String consumerTag);比如handleShutdownSignal 方法,当Channel 或者Connection 关闭的时候会调用。再者,handleConsumeOk 方法会在其他方法之前调用,返回消费者标签。重写handleCancelOk 和handleCancel 方法,这样消费端可以在显式地或者隐式地取消订阅的时候调用。也可以通过channel.basicCancel 方法来显式地取消一个消费者的订阅:
channel.basicCancel(consumerTag);注意上面这行代码会首先触发handleConsumerOk 方法,之后触发handleDelivery方法,最后才触发handleCancelOk 方法。
和生产者一样,消费者客户端同样需要考虑线程安全的问题。消费者客户端的这些callback会被分配到与Channel 不同的线程池上, 这意味着消费者客户端可以安全地调用这些阻塞方
法,比如channel.queueDeclare 、channel.basicCancel 等。
每个Channel 都拥有自己独立的线程。最常用的做法是一个Channel 对应一个消费者,也就是意味着消费者彼此之间没有任何关联。当然也可以在一个Channel 中维持多个消费者,但是要注意一个问题,如果Channel 中的一个消费者一直在运行,那么其他消费者的callback会被"耽搁"。
2.4.2、拉模式
通过channel.basicGet 方法可以单条地获取消息,其返回值是GetResponeo Channel 类的basicGet 方法没有其他重载方法,只有:
GetResponse basicGet(String queue, boolean autoAck) throws IOException;其中queue 代表队列的名称,如果设置autoAck 为false , 那么同样需要调用channel.basicAck 来确认消息己被成功接收。关键代码如下所示:
GetResponse response = channel.basicGet(QUEUE_NAME , false) ;
System.out.println(new String(response.getBody()));
channel.basicAck(response.getEnvelope().getDeliveryTag(),false);特别注意:Basic . Consume 将信道(Channel) 直为接收模式,直到取消队列的订阅为止。在接收模式期间, RabbitMQ 会不断地推送消息给消费者,当然推送消息的个数还是会受到Basic.Qos的限制.如果只想从队列获得单条消息而不是持续订阅,建议还是使用Basic.Get 进行消费.但是不能将Basic.Get 放在一个循环里来代替Basic.Consume ,这样做会严重影响RabbitMQ的性能.如果要实现高吞吐量,消费者理应使用Basic.Consume 方法。
2.5、消费端的确认与拒绝
为了保证消息从队列可靠地达到消费者, RabbitMQ 提供了消息确认机制( message acknowledgement) 。消费者在订阅队列时,可以指定autoAck 参数,当autoAck 等于false时,RabbitMQ 会等待消费者显式地回复确认信号后才从内存(或者磁盘)中移去消息(实质上是先打上删除标记,之后再删除) 。当autoAck 等于true 时, RabbitMQ 会自动把发送出去的消息置为确认,然后从内存(或者磁盘)中删除,而不管消费者是否真正地消费到了这些消息。
采用消息确认机制后,只要设置autoAck 参数为false ,消费者就有足够的时间处理消息(任务) ,不用担心处理消息过程中消费者进程挂掉后消息丢失的问题, 因为RabbitMQ 会一直等待持有消息直到消费者显式调用Basic.Ack 命令为止。
当a utoAck 参数置为false ,对于RabbitMQ 服务端而言,队列中的消息分成了两个部分:一部分是等待投递给消费者的消息:一部分是己经投递给消费者,但是还没有收到消费者确认
信号的消息。如果RabbitMQ 一直没有收到消费者的确认信号,并且消费此消息的消费者己经断开连接,则RabbitMQ 会安排该消息重新进入队列,等待投递给下一个消费者,当然也有可
能还是原来的那个消费者。
RabbitMQ 不会为未确认的消息设置过期时间,它判断此消息是否需要重新投递给消费者的唯一依据是消费该消息的消费者连接是否己经断开,这么设计的原因是RabbitMQ 允许消费者
消费一条消息的时间可以很久很久。
RabbtiMQ 的Web 管理平台上可以看到当前队列中的" Ready" 状态和"Unacknowledged" 状态的消息数,分别对应上文中的等待投递给消费者的消息数和己经投递给消费者但是未收到确认信号的消息数

在消费者接收到消息后,如果想明确拒绝当前的消息而不是确认,那么应该怎么做呢?RabbitMQ 在2 .0.0 版本开始引入了Basic.Reject 这个命令,消费者客户端可以调用与其对应的channel.basicReject 方法来告诉RabbitMQ 拒绝这个消息。Channel 类中的basicReject 方法定义如下:
void basicReject(long deliveryTag, boolean requeue) throws IOException;其中deliveryTag 可以看作消息的编号,它是一个64 位的长整型值,最大值是 9223372036854775807 。如果requeue 参数设置为true ,则RabbitMQ 会重新将这条消息存入队列,以便可以发送给下一个订阅的消费者;如果requeue 参数设置为false ,则RabbitMQ立即会把消息从队列中移除,而不会把它发送给新的消费者。
Basic.Reject 命令一次只能拒绝一条消息,如果想要批量拒绝消息,则可以使用Basic.Nack 这个命令。消费者客户端可以调用channel.basicNack 方法来实现,方法定义如下:
void basicNack(long deliveryTag, boolean multiple , boolean requeue) throws IOException;其中deliveryTag 和requeue 的含义可以参考basicReject 方法。multiple 参数设置为false 则表示拒绝编号为deliveryTag 的这一条消息,这时候basicNack 和 basicReject 方法一样; multiple 参数设置为true 则表示拒绝deliveryTag 编号之前所有未被当前消费者确认的消息。
特别注意:将channel.basicReject 或者channel.basicNack 中的requeue 设置为false ,可以启用"死信队列"的功能。死信队列可以通过检测被拒绝或者未送达的消息来追踪问题
对于requeue , AMQP 中还有一个命令Basic.Recover 具备可重入队列的特性。其对应的客户端方法为:
Basic.RecoverOk basicRecover() throws IOException;Basic.RecoverOk basicRecover(boolean requeue) throws IOException; 这个channel.basicRecover 方法用来请求RabbitMQ 重新发送还未被确认的消息。如果requeue 参数设置为true ,则未被确认的消息会被重新加入到队列中,这样对于同一条消息来说,可能会被分配给与之前不同的消费者。如果requeue 参数设置为false ,那么同一条消息会被分配给与之前相同的消费者。默认情况下,如果不设置requeue 这个参数,相当于
channel.basicRecover(true) ,即requeue 默认为true。
3、Rabbitmq 进阶操作
mandatory 和immediate 是channel . basicPublish 方法中的两个参数,它们都有当消息传递过程中不可达目的地时将消息返回给生产者的功能。RabbitMQ 提供的备份交换器(Altemate Exchange) 可以将未能被交换器路由的消息(没有绑定队列或者没有匹配的绑定〉存储起来,而不用返回给客户端。
3.1、什么是 mandatory 参数
当mandatory 参数设为true 时,交换器无法根据自身的类型和路由键找到一个符合条件的队列,那么RabbitMQ 会调用Basic.Return 命令将消息返回给生产者。当mandatory 参数设置为false 时,出现上述情形,则消息直接被丢弃。
那么生产者如何获取到没有被正确路由到合适队列的消息呢?这时候可以通过调用 channel.addReturnListener 来添加ReturnListener 监昕器实现。示例代码如下所示:
channel.basicPublish(EXCHANGE NAME , "", true,MessageProperties.PERSISTENT_TEXT_PLAIN,"mandatory test".getBytes());channel.addReturnListener(new ReturnListener() (public void handleReturn(int replyCode , String replyText ,String exchange, String routingKey,AMQP.BasicProperties basicProperties,byte[] body) throws IOException {String message = new String(body);System.out.println( "Basic.Return 返回的结果是: "+message );}});//-------------------------//参数说明:
//mandatory:true:如果exchange根据自身类型和消息routeKey无法找到一个符合条件的queue,
//那么会调用basic.return方法将消息返还给生产者。false:出现上述情形broker会直接将消息扔掉
//
//immediate:true:如果exchange在将消息route到queue(s)时发现对应的queue上没有消费者,那么这条消息不会放入队列中。当与消息routeKey关联的
//所有queue(一个或多个)都没有消费者时,该消息会通过basic.return方法返还给生产者。
void basicPublish(String exchange, String routingKey, boolean mandatory, boolean immediate, BasicProperties props, byte[] body)throws IOException;上面代码中生产者没有成功地将消息路由到队列,此时RabbitMQ 会通过 Basic.Return 返回" mandatory test " 这条消息,之后生产者客户端通过ReturnListener 监昕到了这个事件,上面代码的最后输出应该是" Basic.Retum 返回的结果是: mandatory test "
3.2、 immediate 是什么参数(< 3.0)
当imrnediate 参数设为true 时,如果交换器在将消息路由到队列时发现队列上并不存在任何消费者,那么这条消息将不会存入队列中。当与路由键匹配的所有队列都没有消费者时,该消息会通过Basic.Return 返回至生产者。
概括来说, mandatory 参数告诉服务器至少将该消息路由到一个队列中, 否则将消息返回给生产者。imrnediate 参数告诉服务器, 如果该消息关联的队列上有消费者, 则立刻投递:如果所有匹配的队列上都没有消费者,则直接将消息返还给生产者, 不用将消息存入队列而等待消费者了。
RabbitMQ 3 .0 版本开始去掉了对imrnediate 参数的支持,对此RabbitMQ 官方解释是:imrnediate 参数会影响镜像队列的性能, 增加了代码复杂性,建议采用TTL 和DLX 的方法替代。
3.3、什么是备份交换机
备份交换器,英文名称为Altemate Exchange ,简称庙,或者更直白地称之为"备胎交换器"。生产者在发送消息的时候如果不设置mandat ory 参数, 那么消息在未被路由的情况下将会丢失:如果设置了mandatory 参数,那么需要添加ReturnListener 的编程逻辑,生产者的代码将变得复杂。如果既不想复杂化生产者的编程逻辑,又不想消息丢失,那么可以使用备份交换器,这样可以将未被路由的消息存储在RabbitMQ 中,再在需要的时候去处理这些消息。
可以通过在声明交换器(调用channel.exchangeDeclare 方法)的时候添加alternate-exchange 参数来实现,也可以通过策略(Policy ,详细参考5.3 节)的方式实现。如果两者同时使用,则前者的优先级更高,会覆盖掉Policy 的设置。如下示例:
Map<String, Object> args = new HashMap<String, Object>();
args.put("a1ternate-exchange" , "myAe");
channe1.exchangeDec1are("norma1Exchange", "direct", true, false, args);
channe1.exchangeDec1are("myAe", "fanout", true, fa1se , nu11) ;//常规交换器绑定配置
channe1.queueDec1are("norma1Queue " , true , fa1se , fa1se , nu11);
channe1.queueBind("norma1Queue " , "norma1Exchange" , " norma1Key");//备份交换器与备份队列绑定
channe1.queueDec1are("unroutedQueue", true, fa1se, fa1se, nu11);
channel.queueBind("unroutedQueue", "myAe", "");上面的代码中声明了两个交换器nonnallixchange 和myAe ,分别绑定了nonnalQueue 和umoutedQueue 这两个队列,同时将myAe 设置为nonnallixchange 的备份交换器。注意myAe的交换器类型为fanout 。
如果此时发送一条消息到nonnalExchange 上,当路由键等于" nonnalKey" 的时候,消息能正确路由到nonnalQueue 这个队列中。如果路由键设为其他值,比如"errorKey"即消息不能被正确地路由到与nonnallixchange 绑定的任何队列上,此时就会发送给myAe ,进而发送到unroutedQueue 这个队列。

同样,如果采用Policy 的方式来设置备份交换器,可以参考如下:
rabbitmqctl set_policy AE " ^norma lExchange$" '{"alternate-exchange": "myAE"}'
或者在WEB管控台内添加:

最终效果如下所示:

备份交换器其实和普通的交换器没有太大的区别,为了方便使用,建议设置为fanout 类型,如若读者想设置为direct 或者topic 的类型也没有什么不妥。需要注意的是,消息被重新发送到备份交换器时的路由键和从生产者发出的路由键是一样的。
考虑这样一种情况,如果备份交换器的类型是direct , 并且有一个与其绑定的队列,假设绑定的路由键是keyl , 当某条携带路由键为key2 的消息被转发到这个备份交换器的时候,备份交换器没有匹配到合适的队列,则消息丢失。如果消息携带的路由键为key l,则可以存储到队列中。对于备份交换器,总结了以下几种特殊情况:
- 如果设置的备份交换器不存在,客户端和RabbitMQ 服务端都不会有异常出现,此时消息会丢失。
- 如果备份交换器没有绑定任何队列,客户端和RabbitMQ 服务端都不会有异常出现,此时消息会丢失。
- 如果备份交换器没有任何匹配的队列,客户端和RabbitMQ 服务端都不会有异常出现,此时消息会丢失。
- 如果备份交换器和mandatory 参数一起使用,那么mandatory 参数无效。
3.4、设置消息的过期时间
目前有两种方法可以设置消息的TTL。第一种方法是通过队列属性设置,队列中所有消息都有相同的过期时间。第二种方法是对消息本身进行单独设置,每条消息的TTL 可以不同。如果两种方法一起使用,则消息的TTL 以两者之间较小的那个数值为准。消息在队列中的生存时司一旦超过设置的TTL 值时,就会变成"死信" (Dead Message) ,消费者将无法再收到该消息(这点不是绝对的) 。
方式一:
通过队列属性设置消息TTL 的方法是在channel.queueDeclare 方法中加入x-message -ttl 参数实现的,这个参数的单位是毫秒。如下代码所示:
Map<String, Object> argss = new HashMap<String , Object>();
argss.put("x-message-ttl " , 6000);
channel.queueDeclare(queueName, durable, exclusive, autoDelete, argss);方式二:
通过配置策略的方式来设置TTL:
1、使用shell命令设置:
rabbitmqctl set_policy TTL ".*" '{"message-ttl":60000}' --apply-to queues2、使用HTTP API方式设置
$ curl -i -u root:root -H "content-type:application/json"-X PUT -d'{"auto_delete":false , "durable":true , "arguments":{"x-message-ttl": 60000}}' http://localhost:15672/api/queues/{vhost}/{queuename}3、使用web管控台配置策略

如果不设置TTL.则表示此消息不会过期;如果将TTL 设置为0 ,则表示除非此时可以直接将消息投递到消费者,否则该消息会被立即丢弃,这个特性可以部分替代RabbitMQ 3.0 版本之前的immediate 参数,之所以部分代替,是因为immediate 参数在投递失败时会用 Basic .Return 将消息返回(这个功能可以用死信队列来实现,详细参考后续章节)。
针对每条消息设置TTL 的方法是在channel.basicPublish 方法中加入expiration的属性参数,单位为毫秒。如下代码所示:
//方式一:
AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();
builder.deliveryMode(2); // 持久化消息
builder.expiration("60000");// 设置TTL=60000ms
AMQP.BasicProperties properties = builder.build() ;
channel.basicPublish(exchangeName,routingKey,mandatory,properties,"ttlTestMessage".getBytes());//方式二:
AMQP.BasicProperties properties = new AMQP.BasicProperties();
Properties.setDeliveryMode(2);
properties.setExpiration("60000");
channel.basicPublish(exchangeName, routingKey, mandatory, properties,"ttlTestMessage".getBytes());//方式三:
$ curl -i - u root:root -H " content-type:application/json" -X POST -d '{"properties":{" expiration":"60000"} , "routing_key": "routingkey","payload" :"my body","payload_encoding" : "string"}, http:/localhost:15672/api/exchanges/{vhost}/{exchangename}/publish对于第一种设置队列TTL 属性的方法,一旦消息过期,就会从队列中抹去,而在第二种方法中,即使消息过期,也不会马上从队列中抹去,因为每条消息是否过期是在即将投递到消费者之前判定的。
为什么这两种方法处理的方式不一样?因为第一种方法里,队列中己过期的消息肯定在队列头部, RabbitMQ 只要定期从队头开始扫描是否有过期的消息即可。而第二种方法里,每条消息的过期时间不同,如果要删除所有过期消息势必要扫描整个队列,所以不如等到此消息即将被消费时再判定是否过期, 如果过期再进行删除即可。
3.5、设置队列的TTL
通过channel.queueDeclare 方法中的x-expires 参数可以控制队列被自动删除前处于未使用状态的时间。未使用的意思是队列上没有任何的消费者,队列也没有被重新声明,并且在过期时间段内也未调用过Basic.Get 命令。
设置队列里的TTL 可以应用于类似RPC 方式的回复队列,在RPC 中,许多队列会被创建出来,但是却是未被使用的。RabbitMQ 会确保在过期时间到达后将队列删除,但是不保障删除的动作有多及时。在RabbitMQ 重启后, 持久化的队列的过期时间会被重新计算。
用于表示过期时间的x-expires 参数以毫秒为单位, 井且服从和x-message-ttl 一样的约束条件,不过不能设置为0 。比如该参数设置为1000 ,则表示该队列如果在1 秒钟之内未使用则会被删除。
Map<String, Object> args = new HashMap<String, Object>() ;
args.put("x-expires" , 1800000);
channel.queueDeclare("myqueue" , false , false , false , args) ;3.6、死信队列
DLX ,全称为Dead-Letter-Exchange ,可以称之为死信交换器,也有人称之为死信邮箱。当消息在一个队列中变成死信(dead message) 之后,它能被重新被发送到另一个交换器中,这个交换器就是DLX ,绑定DLX 的队列就称之为死信队列。消息变成死信一般是由于以下几种情况:
- 消息被拒绝(Basic.Reject/Basic.Nack) ,井且设置requeue 参数为false;
- 消息过期;
- 队列达到最大长度。
DLX 也是一个正常的交换器,和一般的交换器没有区别,它能在任何的队列上被指定, 实际上就是设置某个队列的属性。当这个队列中存在死信时, RabbitMQ 就会自动地将这个消息重新发布到设置的DLX 上去,进而被路由到另一个队列,即死信队列。可以监听这个队列中的消息、以进行相应的处理,这个特性与将消息的TTL 设置为0 配合使用可以弥补imrnediate 参数的功能。
通过在channel.queueDeclare 方法中设置x-dead-letter-exchange 参数来为这个队列添加DLX,如下代码所示:
channel.exchangeDeclare("dlx_exchange", "direct"); //创建DLX: dlx_exchange
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-dead-letter-exchange" , "dlx_exchange");
//为队列myqueue 添加DLX
channel.queueDeclare("myqueue" , false , false , false , args);//也可以为这个DLX 指定路由键,如果没有特殊指定,则使用原队列的路由键:
args.put("x-dead-letter-routing-key" , "dlx-routing-key");当然,和之前的创建方式一样除了使用代码的方式实现,也可以使用 Policy 的方式进行设置:
rabbitmqctl set_policy DLX ".*" ' {"dead-letter-exchange":" dlx_exchange" } ' --apply-to queues下面是一个死信队列的创建示例:
channel.exchangeDeclare("exchange.dlx" , "direct" , true);
channel.exchangeDeclare("exchange.normal" , "fanout" , true);//队列配置参数
Map<String , Object> args = new HashMap<String, Object>( );
//指定队列消息的过期时间(TTL)
args.put("x-message-ttl" , 10000);
//声明绑定队列为死信队列(DLX)
args.put("x-dead-letter-exchange", "exchange.dlx");
//声明该绑定的死信队列是指定了具体的路由Key(DLK)
args.put("x-dead-letter-routing-key", "routingkey");channel.queueDeclare("queue.normal", true, false, false, args);
channel.queueBind("queue.normal", "exchange.normal", "");channel.queueDeclare("queue.dlx" , true, false, false, null);
channel.queueBind("queue.dlx", "exchange.dlx" , "routingkey");
channel.basicPublish("exchange.normal", "rk",MessageProperties.PERSISTENT_TEXT_PLAIN, "dlx".getBytes());这里创建了两个交换器exchange.normal 和exchange.dlx , 分别绑定两个队列queue.normal和queue.dlx 。通过web管理平台可以看到两个队列都标记了 “D” ,这个是durable 的缩写,即设置了队列持久化。queue.normal 这个队列还配置了TTL 、DLX 和DLK ,其中DLK 指的是 x-dead-letter-routing-key 这个属性。

生产者首先发送一条携带路由键为 " rk" 的消息,然后经过交换器exchange.normal 顺利地存储到队列queue.normal 中。由于队列queue.normal 设置了过期时间为10s , 在这10s 内没有消费者消费这条消息,那么判定这条消息为过期。由于设置了DLX , 过期之时, 消息被丢给交换器exchange.dlx 中,这时找到与exchange.dlx 匹配的队列queue.dlx , 最后消息被存储在queue.dlx 这个死信队列中。

3.7、延迟队列
延迟队列存储的对象是对应的延迟消息,所谓"延迟消息"是指当消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费。延迟队列的使用场景有很多,比如:
- 订单系统中, 一个用户下单之后通常有3 0 分钟的时间进行支付,如果30 分钟之内
没有支付成功,那么这个订单将进行异常处理,这时就可以使用延迟队列来处理这些
订单了。 - 用户希望通过手机远程遥控家里的智能设备在指定的时间进行工作。这时候就可以将
用户指令发送到延迟队列,当指令设定的时间到了再将指令推送到智能设备。
在AMQP 协议中,或者RabbitMQ 本身没有直接支持延迟队列的功能,但是可以通过前面所介绍的DLX 和TTL 模拟出延迟队列的功能。
如下图所示,不仅展示的是死信队列的用法,也是延迟队列的用法,对于queue.dlx 这个死
信队列来说,同样可以看作延迟队列。假设一个应用中需要将每条消息都设置为10 秒的延迟,
生产者通过exchange.normal 这个交换器将发送的消息存储在queue.normal 这个队列中。消费者
订阅的并非是queue.normal 这个队列,而是queue.dlx 这个队列。当消息从queue.normal 这个队
列中过期之后被存入queue.dlx 这个队列中,消费者就恰巧消费到了延迟10 秒的这条消息。
在真实应用中,对于延迟队列可以根据延迟时间的长短分为多个等级,一般分为5 秒、10秒、30 秒、1 分钟、5 分钟、10 分钟、30 分钟、1 小时这几个维度,当然也可以再细化一下。
为了简化说明,这里只设置了5 秒、10 秒、30 秒、l 分钟这四个等级。根据应用需求的不同,生产者在发送消息的时候通过设置不同的路由键,以此将消息发送到与交换器绑定的不同的队列中。这里队列分别设置了过期时间为5 秒、10 秒、30 秒、1 分钟,同时也分别配置了DLX 和相应的死信队列。当相应的消息过期时,就会转存到相应的死信队列(即延迟队列〉中,这样消费者根据业务自身的情况,分别选择不同延迟等级的延迟队列进行消费。

3.8、优先级队列
优先级队列, 顾名思义,具有高优先级的队列具有高的优先权,优先级高的消息具备优先被消费的特权。可以通过设置队列的x-max-priority 参数来实现。如下代码所示:
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-max-priority", 10);
channel.queueDeclare("queue.priority", true, false, false, args);
上面的代码演示的是如何配置一个队列的最大优先级。在此之后, 需要在发送时在消息中设置消息当前的优先级。可以参考下面的代码:
AMQP.BasicProperties.Bui1der builder = new AMQP.BasicProperties.Builder();
builder.priority(5) ;
AMQP.BasicProperties properties = builder.build();
channel.basicPub1ish("exchange_priority", "rk_priority", properties, ("mnessages").getBytes()) ;上面的代码中设置消息的优先级为5 。默认最低为0 ,最高为队列设置的最大优先级。优先级高的消息可以被优先消费,这个也是有前提的: 如果在消费者的消费速度大于生产者的速度且Broker 中没有消息堆积的情况下, 对发送的消息设置优先级也就没有什么实际意义。因为生产者刚发送完一条消息就被消费者消费了,那么就相当于Broker 中至多只有一条消息,对于单条消息来说优先级是没有什么意义的。
3.9、RPC实现
RPC, 是Remote Procedure Call 的简称,即远程过程调用。它是一种通过网络从远程计算机上请求服务,而不需要了解底层网络的技术。RPC 的主要功用是让构建分布式计算更容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性。
通俗点来说,假设有两台服务器A 和B , 一个应用部署在A 服务器上,想要调用B 服务器上应用提供的函数或者方法,由于不在同一个内存空间, 不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
RPC 的协议有很多,比如最早的CORBA 、Java RMI, WebService 的RPC 风格、Hessian 、Thri负甚至还有Restful API 。一般在RabbitMQ 中进行RPC 是很简单。客户端发送请求消息,服务端回复响应的消息。为了接收响应的消息,我们需要在请求消息中发送一个回调队列(参考下面代码中的replyTo) 。可以使用默认的队列,具体参考下面的代码:
String callbackQueueName = channel.queueDeclare().getQueue();
BasicProperties props = new BasicProperties.Builder().replyTo(callbackQueueName).build();
channel.basicPublish( "","rpc_queue " , props , message.getBytes()) ;
// then code to read a response message from the callback_queue...对于代码中涉及的BasicProperties 这个类,将在后续文章中展开讲解,其包含14 个属性,这里就用到两个属性。
- replyTo: 通常用来设置一个回调队列。
- correlationId : 用来关联请求( request) 和其调用RPC 之后的回复(response ) 。
如果像上面的代码中一样,为每个RPC 请求创建一个回调队列,则是非常低效的。但是幸运的是这里有一个通用的解决方案一一可以为每个客户端创建一个单一的回调队列。这样就产生了一个新的问题,对于回调队列而言,在其接收到一条回复的消息之后,它并不知道这条消息应该和哪一个请求匹配。这里就用到correlationld 这个属性了, 我们应该为每一个请求设置一个唯一的correlationld 。之后在回调队列接收到回复的消息时,可以根据这个属性匹配到相应的请求。如果回调队列接收到一条未知correlationld 的回复消息,可以简单地将其丢弃。
你有可能会问,为什么要将回调队列中的位置消息丢弃而不是仅仅将其看作失败?这样可
以针对这个失败做一些弥补措施。考虑这样一种情况, RPC 服务器可能在发送给回调队列(amq.gen-LhQzlgv3GhDOv8PIDabOXA )并且在确认接收到请求的消息( rpc_queue中的消息)之后挂掉了,那么只需重启下RPC 服务器即可, RPC 服务会重新消费rpc_queue 队列中的请求,这样就不会出现RPC 服务端未处理请求的情况。这里的回调队列可能会收到重复消息的情况,这需要客户端能够优雅地处理这种情况,并且RPC 请求也需要保证其本身是幂等的(补充: 根据2.5 节的介绍,消费者消费消息一般是先处理业务逻辑, 再使用Basic.Ack确认己接收到消息以防止消息不必要地丢失)。

- 当客户端启动时,创建一个匿名的回调队列(名称由RabbitMQ 自动创建,图中的回调队列为amq.gen-LhQzlgv3GhDOv8PIDabOXA ) 。
- 客户端为RPC 请求设置2 个属性: replyTo 用来告知RPC 服务端回复请求时的目的队列,即回调队列; correlationld 用来标记一个请求。
- 请求被发送到rpc_queue 队列中。
- RPC 服务端监听rpc_queue 队列中的请求,当请求到来时, 服务端会处理并且把带有结果的消息发送给客户端。接收的队列就是replyTo 设定的回调队列。
- 客户端监昕回调队列, 当有消息时, 检查correlationld 属性,如果与请求匹配,那就是结果了。
下面沿用RabbitMQ 官方网站的一个例子来做说明,RPC 客户端通过RPC 来调用服务端的方法以便得到相应的斐波那契值。
【RPC server】
package com.blnp.net.rabbitmq.rpc;import com.rabbitmq.client.*;import java.io.IOException;
import java.util.concurrent.TimeoutException;/*** <p></p>** @author lyb 2045165565@qq.com* @createDate 2023/9/9 11:25*/
public class RpcServer {private static final String IP_ADDRESS = "192.168.56.106";/*** RabbitMQ 服务端默认端口号为5672**/private static final int PORT = 5672;private static final String RPC_QUEUE_NAME = "rpc_queue";public static void main(String[] args) throws IOException, TimeoutException {ConnectionFactory factory = new ConnectionFactory();factory.setHost(IP_ADDRESS);factory.setPort(PORT);factory.setUsername("admin");factory.setPassword("admin@123");//创建mq连接Connection connection = factory.newConnection();//创建信道Channel channel = connection.createChannel();channel.queueDeclare(RPC_QUEUE_NAME, false , false , false , null) ;channel.basicQos (1) ;System.out.println("[x] Awaiting RPC requests" );Consumer consumer = new DefaultConsumer(channel) {@Overridepublic void handleDelivery(String consumerTag, Envelope envelope,AMQP.BasicProperties properties, byte[] body) throws IOException {AMQP.BasicProperties replyProps = new AMQP.BasicProperties.Builder().correlationId(properties.getCorrelationId()).build() ;String response = "";try {String message = new String(body,"utf-8") ;int n = Integer.parseInt(message) ;System.out.println(" [ . ] fib( " + message + " ) " );response += fib(n) ;} catch (RuntimeException e){System.out.println(" [.] " + e.toString());}finally {channel.basicPublish("",properties.getReplyTo(),replyProps, response.getBytes("UTF-8"));channel.basicAck(envelope.getDeliveryTag(), false);}}};channel.basicConsume(RPC_QUEUE_NAME, false, consumer) ;//关闭资源channel.close();connection.close();}private static int fib(int n) {if(n == 0) {return 0;}if(n == 1) {return 1;}return fib(n - 1) + fib(n - 2) ;}
}
【RPC Client】
package com.blnp.net.rabbitmq.rpc;import com.rabbitmq.client.*;import java.io.IOException;
import java.util.UUID;
import java.util.concurrent.TimeoutException;/*** <p></p>** @author lyb 2045165565@qq.com* @createDate 2023/9/9 11:36*/
public class RpcClient {private Connection connection;private Channel channel;private String requestQueueName = "rpc_queue";private String replyQueueName;private QueueingConsumer consumer;private static final String IP_ADDRESS = "192.168.56.106";/*** RabbitMQ 服务端默认端口号为5672**/private static final int PORT = 5672;public RpcClient() throws IOException, TimeoutException {ConnectionFactory factory = new ConnectionFactory();factory.setHost(IP_ADDRESS);factory.setPort(PORT);factory.setUsername("admin");factory.setPassword("admin@123");//创建mq连接connection = factory.newConnection();//创建信道channel = connection.createChannel();replyQueueName = channel.queueDeclare().getQueue();consumer = new QueueingConsumer (channel);channel.basicConsume(replyQueueName, true, consumer);}public String call(String message) throws IOException, ShutdownSignalException,ConsumerCancelledException,InterruptedException {String response = null ;String corrId = UUID.randomUUID().toString();BasicProperties props = new AMQP.BasicProperties.Builder().correlationId (corrId).replyTo(replyQueueName).build();channel.basicPublish ("", requestQueueName, (AMQP.BasicProperties) props, message.getBytes());while (true) {QueueingConsumer.Delivery delivery = consumer.nextDelivery();if (delivery.getProperties().getCorrelationId().equals(corrId)) {response = new String(delivery.getBody());break;}}return response;}public void close() throws Exception {connection.close();}public static void main(String[] args) throws Exception {RpcClient fibRpc = new RpcClient() ;System.out.println(" [x) Requesting fib(30)");String response = fibRpc.call("30");System.out.println(" [.) Got '" +response+ "'" );fibRpc.close() ;}
}
3.10、持久化
"持久化"这个词汇在前面的篇幅中有多次提及,持久化可以提高RabbitMQ 的可靠性, 以防在异常情况(重启、关闭、宕机等)下的数据丢失。本节针对这个概念做一个总结。RabbitMQ的持久化分为三个部分:交换器的持久化、队列的持久化和消息的持久化。
交换器的持久化是通过在声明队列是将durable 参数置为true 实现的,详细可以参考2.2节。如果交换器不设置持久化,那么在RabbitMQ 服务重启之后,相关的交换器元数据会丢失,不过消息不会丢失,只是不能将消息发送到这个交换器中了。对一个长期使用的交换器来说,建议将其置为持久化的。
队列的持久化能保证其本身的元数据不会因异常情况而丢失,但是并不能保证内部所存储的消息不会丢失。要确保消息不会丢失, 需要将其设置为持久化。通过将消息的投递模式
(BasicProperties 中的deliveryMode 属性)设置为2 即可实现消息的持久化。前面示例中多次提及的MessageProperties.PERSISTENT_TEXT_PLAIN 实际上是封装了这个属性:
public static final BasicProperties PERSISTENT_TEXT_PLAIN =
new BasicProperties("text/plain", null, null,
2, //deliveryMode
0, null, null, null,
null, null, null, null,
null, null);设置了队列和消息的持久化,当RabbitMQ 服务重启之后,消息依旧存在。单单只设置队列持久化,重启之后消息会丢失;单单只设置消息的持久化,重启之后队列消失,继而消息也丢失。单单设置消息持久化而不设置队列的持久化显得毫无意义。
注意要点:可以将所有的消息都设置为持久化,但是这样会严重影响RabbitMQ 的性能(随机)。写入磁盘的速度比写入内存的速度慢得不只一点点。对于可靠性不是那么高的消息可以不采用持久化处理以提高整体的吞吐量。在选择是否要将消息持久化时,需要在可靠性和吞吐量之间做一个权衡。
将交换器、队列、消息都设置了持久化之后就能百分之百保证数据不丢失了吗?答案是否定的。
首先从消费者来说,如果在订阅消费队列时将autoAck 参数设置为true ,那么当消费者接收到相关消息之后,还没来得及处理就宕机了,这样也算数据丢失。这种情况很好解决,将autoAck 参数设置为false , 并进行手动确认。
其次,在持久化的消息正确存入RabbitMQ 之后,还需要有一段时间(虽然很短,但是不可忽视〉才能存入磁盘之中。RabbitMQ 并不会为每条消息都进行同步存盘(调用内核的fsync方法)的处理,可能仅仅保存到操作系统缓存之中而不是物理磁盘之中。如果在这段时间内RabbitMQ 服务节点发生了岩机、重启等异常情况,消息保存还没来得及落盘,那么这些消息将会丢失。
fsync:在Linux 中的意义在于同步数据到存储设备上。大多数块设备的数据都是通过缓存进行的,将数据写到文件上通常将该数据由内核复制到缓存中,如果缓存尚未写满,则不将其排入输出队列上,而是等待其写满或者当内核需要重用该缓存时,再将该缓存排入输出队列,进而同步到设备上。这种策略的好处是减少了磁盘读写次数,不足的地方是降低了文件内容的更新速度,使其不能时刻同步到存储设备上, 当系统发生故障时,这种机制很有可能导致了文件内容的丢失。因此,内核提供了fsync接口,用户可以根据自己的需要通过此接口更新数据到存储设备上.
这个问题怎么解决呢?这里可以引入RabbitMQ 的镜像队列机制,相当于配置了副本,如果主节点(master ) 在此特殊时间内挂掉,可以自动切换到从节点(slave ),这样有效地保证了高可用性,除非整个集群都挂掉。虽然这样也不能完全保证RabbitMQ 消息不丢失,但是配置了镜像队列要比没有配置镜像队列的可靠性要高很多,在实际生产环境中的关键业务队列一般都会设置镜像队列。
还可以在发送端引入事务机制或者发送方确认机制来保证消息己经正确地发送并存储至RabbitMQ 中,前提还要保证在调用channel.basicPublish 方法的时候交换器能够将消息正确路由到相应的队列之中。
3.11、关于生产者的确认机制
在使用RabbitMQ 的时候,可以通过消息持久化操作来解决因为服务器的异常崩溃而导致的消息丢失,除此之外,我们还会遇到一个问题,当消息的生产者将消息发送出去之后,消息到底有没有正确地到达服务器呢?如果不进行特殊配置,默认情况下发送消息的操作是不会返回任何信息给生产者的,也就是默认情况下生产者是不知道消息有没有正确地到达服务器。如果在消息到达服务器之前己经丢失,持久化操作也解决不了这个问题,因为消息根本没有到达服务器,何谈持久化?RabbitMQ 针对这个问题,提供了两种解决方式:
- 过事务机制实现
- 通过发送方确认C publisher confirm ) 机制实现。
3.11.1、事务机制
RabbitMQ 客户端中与事务机制相关的方法有三个: channel.txSelect 、channel.txCommit 和channel.txRollback。channel.txSelect 用于将当前的信道设置成事务模式. channel.txCommit 用于提交事务. channel.txRollback 用于事务回滚。在通过channel.txSelect 方法开启事务之后,我们便可以发布消息给RabbitMQ 了,如果事务提交成功,则消息一定到达了RabbitMQ 中,如果在事务提交执行之前由于RabbitMQ 异常崩溃或者其他原因抛出异常,这个时候我们便可以将其捕获,进而通过执行 channel.txRollback 方法来实现事务回夜。注意这里的RabbitMQ 中的事务机制与大多数数据库中的事务概念井不相同,需要注意区分。如下代码所示:
channel.txSelect();
channel.basicPublish(EXCHANGE_NAME , ROUTING_KEY,
MessageProperties.PERSISTENT_TEXT_PLAIN,
"transaction messages".getBytes());
channel.txCommit();
可以发现开启事务机制与不开启相比(不开启的流程图可参考前文)多了四个步骤:
- 客户端发送Tx.Select. 将信道置为事务模式
- Broker 回复Tx.Select-Ok. 确认己将信道置为事务模式:
- 在发送完消息之后,客户端发送Tx.Commit 提交事务;
- Broker 回复Tx.Commi t-Ok. 确认事务提交。
上面所陈述的是正常的情况下的事务机制运转过程,而事务回滚是什么样子呢?我们先来
参考下面一段示例代码. 来看看怎么使用事务回滚。
try {channel.txSelect();channel.basicPublish(exchange, routingKey,MessageProperties.PERSISTENT_TEXT_PLAIN , msg.getBytes());int result = 1 / 0;channel.txCommit();
} catch (Exception e) {e.printStackTrace();channel.txRollback();
}上面代码中很明显有一个java.lang.ArithmeticException. 在事务提交之前捕获到异常,之后显式地提交事务回滚,其AMQP 协议流转过程如图所示:

如果要发送多条消息,则将channel.basicPublish 和channel.txCommit 等方法包裹进循环内即可,可以参考如下示例代码:
channel.txSelect();
for (int i=O; i<LOOP_TIMES; i++) {try {channel.basicPublish ("exchange", "routingKey", null, ("messages" + i).getBytes());channel .txCommit( );} catch (IOException e) {e.printStackTrace();channel.txRollback();}
}事务确实能够解决消息发送方和RabbitMQ 之间消息确认的问题,只有消息成功被 RabbitMQ 接收,事务才能提交成功,否则便可在捕获异常之后进行事务回滚,与此同时可以进行消息重发。但是使用事务机制会"吸干" RabbitMQ 的性能,那么有没有更好的方法既能保证消息发送方确认消息已经正确送达,又能基本上不带来性能上的损失呢?从AMQP 协议层面来看并没有更好的办法,但是RabbitMQ 提供了一个改进方案,即发送方确认机制,详情请看下一节的介绍。
3.11.2、发送方确认机制
前面介绍了RabbitMQ 可能会遇到的一个问题,即消息发送方(生产者〉并不知道消息是否真正地到达了RabbitMQ。随后了解到在AMQP 协议层面提供了事务机制来解决这个问题,但是采用事务机制实现会严重降低RabbitMQ 的消息吞吐量,这里就引入了一种轻量级的方式,即发送方确认( publisher confirm) 机制。
生产者将信道设置成confmn ( 确认)模式,一旦信道进入confmn 模式,所有在该信道上
面发布的消息都会被指派一个唯一的ID(从 1 开始),一旦消息被投递到所有匹配的队列之后,RabbitMQ 就会发送一个确认(Basic.Ack) 给生产者(包含消息的唯一ID) ,这就使得生产者知晓消息已经正确到达了目的地了。如果消息和队列是可持久化的,那么确认消息会在消息写入磁盘之后发出。RabbitMQ 回传给生产者的确认消息中的 deliveryTag 包含了确认消息的序号,此外RabbitMQ 也可以设置channel. basicAck 方法中的multiple 参数,表示到这个序号之前的所有消息都己经得到了处理,可以下图 。注意辨别这里的确认和消费时候的确认之间的异同。

事务机制在一条消息发送之后会使发送端阻塞,以等待RabbitMQ 的回应,之后才能继续发送下一条消息。相比之下, 发送方确认机制最大的好处在于它是异步的,一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继续发送下一条消息,当消息最终得到确认之后,生产者应用程序便可以通过回调方法来处理该确认消息,如果RabbitMQ 因为自身内部错误导致消息丢失,就会发送一条 nack (Basic.Nack) 命令,生产者应用程序同样可以在回调方法中处理该nack 命令。
生产者通过调用channel.confirmSelect 方法(即Confirm.Select 命令)将信道设置为confrrm 模式,之后RabbitMQ 会返回Confirm.Select-Ok 命令表示同意生产者将当前信道设置为confirm 模式。所有被发送的后续消息都被ack 或者nack 一次,不会出现一条消息既被ack 又被nack 的情况, 并且RabbitMQ 也并没有对消息被confrrm 的快慢做任何保证。如下示例代码:
try {//将信道设置为【发送确认机制】channel.confirmSelect();channel.basicPublish("exchange","routingKey",null,"public message".getBytes());if (!channel.waitForConfirms()) {System.out.println("send message failed");//do something else}
}catch (InterruptedException e) {e.printStackTrace();
}如果发送多条消息,只需要将channel.basicPublish 和channel.waitForConfirms 方法包裹在循环里面即可,可以参考事务机制,不过不需要把channel.confirmSelect 方法包裹在循环内部。在publisher confirm 模式下发送多条消息的AMQP 协议流转过程可以参考下图:
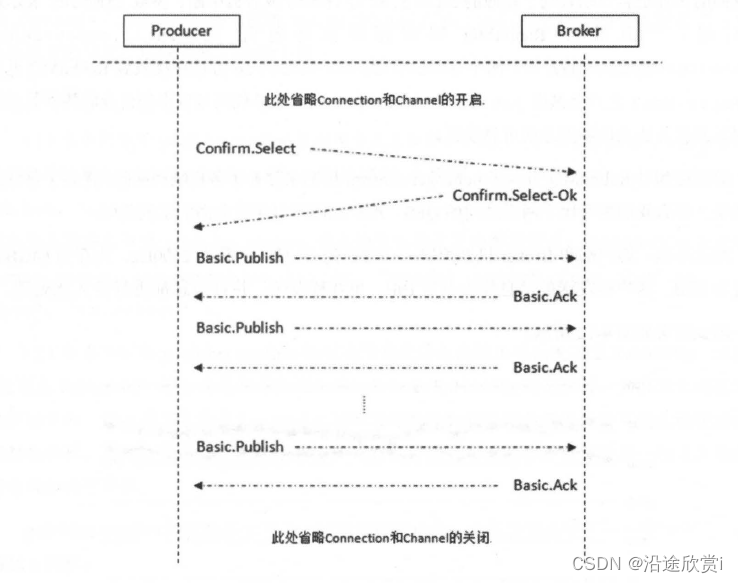
对于channel.waitForConfirms 而言,在RabbitMQ 客户端中它有4 个同类的方法:
- boolean waitForConfirms() throws InterruptedException;
- boolean waitForConfirms(long timeout) throws InterruptedException,TimeoutException;
- void waitForConfirmsOrDie() throws IOException, InterruptedException;
- void waitForConfirmsOrDie(long timeout) throws IOException, InterruptedException, TimeoutException ;
如果信道没有开启publisher confirm 模式,则调用任何waitForConfirms 方法都会报出java.lang.IllegalStateException。对于没有参数的waitForConfirms 方法来说,其返回的条件是客户端收到了相应的Basic.Ack/.Nack 或者被中断。参数timeout 表示超时时间, 一旦等待RabbitMQ 回应超时就会抛出java.util. concurrent.TimeoutException 的异常。两个waitForConfirmsOrDie 方法在接收到RabbitMQ 返回的Basic.Nack 之后会抛出java.io.IOException 。业务代码可以根据自身的特性灵活地运用这四种方法来保障消息的可靠发送。
前面提到过RabbitMQ 引入了publisher confirm 机制来弥补事务机制的缺陷,提高了整体的吞吐量,那么我们来对比下两者之间的QPS ,测试代码可以参考上面的示例代码。
测试环境:客户端和Broker 机器配置 一 CPU 为24 核、主频为2600Hz、内存为64GB 、
硬盘为1TB 。客户端发送的消息体大小为10B ,单线程发送,并且消息都进行持久化处理。

图中的横坐标表示测试的次数,纵坐标表示QPS 。可以发现publisher confum 与事务机制相比, QPS 井没有提高多少,难道是RabbitMQ 欺骗了我们?
我们再来回顾下前面的示例代码,可以发现 publisher confmn 模式是每发送一条消息后就调用channel.waitForConfirms 方法,之后等待服务端的确认,这实际上是一种串行同步等待的方式。事务机制和它一样,发送消息之后等待服务端确认,之后再发送消息。两者的存储确认原理相同,尤其对于持久化的消息来说,两者都需要等待消息确认落盘之后才会返回(调用Linux 内核的fsync 方法) 。在同步等待的方式下, publisher confum 机制发送一条消息需要通信交互的命令是2 条:Basic.Publish 和Basic.Ack; 事务机制是3 条:Basic.Publish 、Tx.Commmit / .Commit-Ok (或者Tx.Rollback /.Rollback -Ok) , 事务机制多了一个命令帧报文的交互,所以QPS 会略微下降。
注意要点:
- 事务机制和 publisher confirm 机制两者是互斥的,不能共存。如果企图将已开启事务模式的信道再设置为 publisher confmn 模式, RabbitMQ 会报错{amqp_error, precondition_failed, "cannot switch from tx to confirm mode" , 'confirm.select '}; 或者如果企图将已开启publisher confum 模式的信道再设直为事务模式, RabbitMQ 也会报错:{amqp_error, precondition_failed, "cannot switch from confirm to tx mode", 'tx.select'}.
- 事务机制和 publisher confum 机制确保的是消息能够正确地发送至RabbitMQ ,这里的"发送至RabbitMQ" 的含义是指消息被正确地发往至RabbitMQ 的交换器,如果此交换器没有匹配的队列,那么消息也会丢失。所以在使用这两种机制的时候要确保所涉及的交换器能够有匹配的队列. 更进一步地讲,发送方要配合 mandatory 参数或者备份交换器一起使用来提高消息传输的可靠性。
publisher confmn 的优势在于并不一定需要同步确认。这里我们改进了一下使用方式,总结有如下两种:
- 批量confirm 方法:每发送一批消息后,调用channel.waitForConfirms 方法,等待服务器的确认返回。
- 异步confirm 方法:提供一个回调方法,服务端确认了一条或者多条消息后客户端会回调这个方法进行处理
在批量confmn 方法中,客户端程序需要定期或者定量(达到多少条),亦或者两者结合起来调用channel.waitForConfirms 来等待RabbitMQ 的确认返回。相比于前面示例中的普通confmn 方法,批量极大地提升了confmn 的效率,但是问题在于出现返回Basic.Nack 或者超时情况时,客户端需要将这一批次的消息全部重发,这会带来明显的重复消息数量,并且当消息经常丢失时,批量confirm 的性能应该是不升反降的。
【批量 Confirm 示例代码】
try {channel.confirmSelect();int msgCount = 0;while(true) {channel.basicPublish( "exchange","routingKey " , null, "message".getBytes());//将发送出去的消息存入缓存中,缓存可以是一个 ArrayList 或者 BlockingQueue 之类的if (++msgCount >= BATCH_COUNT) {msgCount = 0;try {if (channel.waitForConfirms()) {//将缓存中的消息清空}//将缓存中的消息进行重新发送}catch (InterruptedException e) {e.printStackTrace();//将缓存中的消息进行重新发送}}}
}catch (IOException e) {e.printStackTrace();
}异步confmn 方法的编程实现最为复杂。在客户端Channel 接口中提供的 addConfirmListener 方法可以添加ConfirmListener 这个回调接口,这个ConfirmListener 接口包含两个方法: handleAck 和handleNack ,分别用来处理 RabbitMQ 回传的Basic.Ack 和Basic.Nack 。在这两个方法中都包含有一个参数 deliveryTag (在publisher confirm 模式下用来标记消息的唯一有序序号)。我们需要为每一个信道维护一个" unconfirm " 的消息序号集合, 每发送一条消息,集合中的元素加1 。每当调用ConfirmListener 中的handleAck 方法时, " unconfirm " 集合中删掉相应的一条(multiple 设置为false ) 或者多条(multiple 设置为true ) 记录。从程序运行效率上来看,这个" unconfrrm "集合最好采用有序集合SortedSet 的存储结构。事实上, Java 客户端SDK中的waitForConfirms 方法也是通过SortedSet 维护消息序号的。如下代码演示了异步confrrm 的编码实现, 其中的confirmSet 就是一个SortedSet 类型的集合。
channel.confirmSelect();
channel.addConfirmListener(new ConfirmListener() {@Overridepublic void handleAck(long deliveryTag, boolean multiple) throws IOException {if (multiple) {confirmSet.headSet(deliveryTag - 1).clear();}else {confirmSet.remove(deliveryTag);}}@Overridepublic void handleNack(long deliveryTag, boolean multiple) throws IOException {if (multiple) {confirmSet.headSet(deliveryTag - 1).clear();}else {confirmSet.remove(deliveryTag);}//注意这里需要添加处理消息重发的场景}
});//下面是演示一直发送消息的场景
while(true){long nextSeqNo = channel.getNextPublishSeqNo();channel.basicPublish(ConfirmConfig.exchangeName, ConfirmConfig.routingKey, MessageProperties.PERSISTENT_TEXT_PLAIN, ConfirmConfig.msg_10B.getBytes());confirmSet.add(nextSeqNo);
}最后我们将事务、普通confrrm、批量confrrm 和异步confrrm 这4 种方式放到一起来比较一下彼此的QPS。
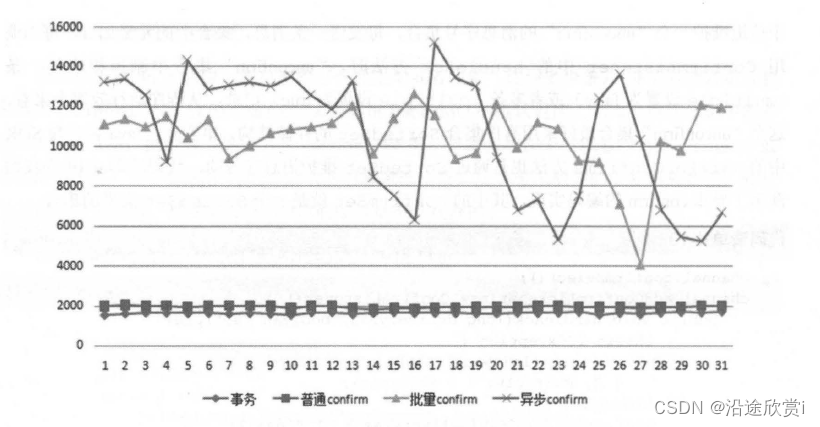
可以看到批量confmn 和异步confinn 这两种方式所呈现的性能要比其余两种好得多。事务机制和普通confmn 的方式吐吞量很低,但是编程方式简单,不需要在客户端维护状态(这里指的是维护deliveryTag 及缓存未确认的消息)。批量confmn 方式的问题在于遇到RabbitMQ服务端返回Basic.Nack 需要重发批量消息而导致的性能降低。异步confinn 方式编程模型最为复杂,而且和批量confmn 方式一样需要在客户端维护状态。在实际生产环境中采用何种方式,这里就仁者见仁智者见智了,不过强烈建议读者使用异步confmn 的方式。
3.12、消费端要点说明
消费者客户端可以通过推模式或者拉模式的方式来获取并消费消息,当消费者处理完业务逻辑需要手动确认消息己被接收,这样RabbitMQ才能把当前消息从队列中标记清除。当然如果消费者由于某些原因无法处理当前接收到的消息,可以通过channel.basicNack 或 channel.basicReject 来拒绝掉。这里对于RabbitMQ 消费端来说,还有几点需要注意:
- 消息分发
- 消息顺序性
- 弃用 QueueingConsumer
3.12.1、消息分发
当RabbitMQ 队列拥有多个消费者时,队列收到的消息将以轮询(round-robin )的分发方式发送给消费者。每条消息只会发送给订阅列表里的一个消费者。这种方式非常适合扩展,而且它是专门为并发程序设计的。如果现在负载加重,那么只需要创建更多的消费者来消费处理消息即可。
很多时候轮询的分发机制也不是那么优雅。默认情况下,如果有n 个消费者,那么RabbitMQ会将第m 条消息分发给第m%n (取余的方式)个消费者, RabbitMQ 不管消费者是否消费并己经确认(Basic.Ack) 了消息。试想一下,如果某些消费者任务繁重,来不及消费那么多的消息,而某些其他消费者由于某些原因(比如业务逻辑简单、机器性能卓越等)很快地处理完了所分配到的消息,进而进程空闲,这样就会造成整体应用吞吐量的下降。
那么该如何处理这种情况呢?这里就要用到channel.basicQos(int prefetchCount)这个方法,如前面章节所述, channel.basicQos 方法允许限制信道上的消费者所能保持的最大未确认消息的数量。
举例说明,在订阅消费队列之前,消费端程序调用了channel.basicQos(5) ,之后订阅了某个队列进行消费。RabbitMQ 会保存一个消费者的列表,每发送一条消息都会为对应的消费者计数,如果达到了所设定的上限,那么RabbitMQ 就不会向这个消费者再发送任何消息。直到消费者确认了某条消息之后, RabbitMQ 将相应的计数减1,之后消费者可以继续接收消息,直到再次到达计数上限。这种机制可以类比于TCP/IP中的"滑动窗口"。
注意说明:Basic.Qos 的使用对于拉模式的消费方式无效.
channel.basicQos 有三种类型的重载方法,如下所示:
void basicQos(int prefetchCount) throws IOException;void basicQos(int prefetchCount, boo1ean global) throws IOException;void basicQos(int prefetchSize, int prefetchCount, boo1ean global) throws IOException;前面介绍的都只用到了prefetchCount 这个参数,当prefetchCount 设置为0 则表示没有上限。还有prefetchSize 这个参数表示消费者所能接收未确认消息的总体大小的上限,单位为B ,设置为0 则表示没有上限。
对于一个信道来说,它可以同时消费多个队列,当设置了prefetchCount 大于0 时,这个信道需要和各个队列协调以确保发送的消息都没有超过所限定的prefetchCount 的值,这样会使RabbitMQ 的性能降低,尤其是这些队列分散在集群中的多个Broker 节点之中。RabbitMQ 为了提升相关的性能,在AMQPO-9-1 协议之上重新定义了global 这个参数,对比如下表所示。
| global参数 | AMQP 0-9-1 | Rabbitmq |
|---|---|---|
| false | 信道上所有的消费者都需要遵从 prefetchCount 的限定值 | 信道上新的消费者需要遵从 prefetchCount 的限定值 |
| true | 当前通信链路(Contenction)上所有的消费者都需要遵从 prefetchCount 的限定值 | 信道上所有的消费者需要遵从 prefetchCount 的限定值 |
channel.basicQos 方法的示例都是针对单个消费者的,而对于同一个信道上的多个消费者而言,如果设置了prefetchCount 的值,那么都会生效。下面示例中有两个消费者,各自的能接收到的未确认消息的上限都为10
channel.basicQos(10); // Per consumer 1imit
channel.basicConsume("my-queue1", false, consumer1);
channel.basicConsume("my-queue2", false, consumer2);如果在订阅消息之前,既设置了global 为true 的限制,又设置了global 为false 的限制,那么哪个会生效呢? RabbitMQ 会确保两者都会生效。举例说明,当前有两个队列queue1和queue2: queue1 有10 条消息,分别为1 到10; queue2 也有1 0 条消息,分别为11 到20 。有两个消费者分别消费这两个队列:
channel.basicQos(3, false); // Per consumer limit
channel.basicQos(5, true); // Per channel limit
channel.basicConsume("queuel", false , consumerl);
channel.basicConsume("queue2 " , false , consumer2);那么这里每个消费者最多只能收到3 个未确认的消息,两个消费者能收到的未确认的消息个数之和的上限为5 。在未确认消息的情况下,如果consumerl 接收到了消息1 、2 和3 ,那么consumer2 至多只能收到11 和12 。如果像这样同时使用两种global 的模式,则会增加RabbitMQ的负载,因为RabbitMQ 需要更多的资源来协调完成这些限制。如无特殊需要,最好只使用global 为false 的设置,这也是默认的设置。
3.12.2、消息的顺序性
消息的顺序性是指消费者消费到的消息和发送者发布的消息的顺序是一致的。举个例子,不考虑消息重复的情况,如果生产者发布的消息分别为msgl 、msg2 、msg3 ,那么消费者必然也是按照msgl 、msg2 、msg3 的顺序进行消费的。
目前很多资料显示RabbitMQ 的消息能够保障顺序性,这是不正确的,或者说这个观点有很大的局限性。在不使用任何RabbitMQ 的高级特性,也没有消息丢失、网络故障之类异常的情况发生,并且只有一个消费者的情况下,最好也只有一个生产者的情况下可以保证消息的顺序性。如果有多个生产者同时发送消息,无法确定消息到达Broker 的前后顺序,也就无法验证消息的顺序性。
那么哪些情况下RabbitMQ 的消息顺序性会被打破呢?
如果生产者使用了事务机制,在发送消息之后遇到异常进行了事务回滚,那么需要重新补偿发送这条消息,如果补偿发送是在另一个线程实现的,那么消息在生产者这个源头就出现了错序。同样,如果启用publisher confirrn 时,在发生超时、中断,又或者是收到RabbitMQ 的Basic.Nack 命令时,那么同样需要补偿发送,结果与事务机制一样会错序。或者这种说法有些牵强,我们可以固执地认为消息的顺序性保障是从存入队列之后开始的,而不是在发迭的时候开始的。
考虑另一种情形,如果生产者发送的消息设置了不同的超时时间,井且也设置了死信队列,整体上来说相当于一个延迟队列,那么消费者在消费这个延迟队列的时候,消息的顺序必然不会和生产者发送消息的顺序一致。
再考虑一种情形,如果消息设置了优先级,那么消费者消费到的消息也必然不是顺序性的。
如果一个队列按照前后顺序分有msg1 , msg2 、msg3 、msg4 这4 个消息,同时有ConsumerA 和 ConsumerB 这两个消费者同时订阅了这个队列。队列中的消息轮询分发到各个消费者之中,ConsumerA 中的消息为msg1 和msg3 , ConsumerB 中的消息为msg2 、msg4 。 ConsumerA 收到消息msg1 之后并不想处理而调用了Basic.Nack/.Reject 将消息拒绝,与此同时将requeue 设置为true ,这样这条消息就可以重新存入队列中。消息msg1 之后被发送到了ConsumerB 中,此时ConsumerB 己经消费了msg2 、msg4 ,之后再消费msg 1.这样消息顺序性也就错乱了。或者消息msg1 又重新发往ConsumerA 中,此时ConsumerA 己经消费了msg3 ,那么再消费msg1 ,消息顺序性也无法得到保障。同样可以用在Basic.Recover 这个AMQP命令中。
包括但不仅限于以上几种情形会使RabbitMQ 消息错序。如果要保证消息的顺序性,需要业务方使用RabbitMQ 之后做进一步的处理,比如在消息体内添加全局有序标识(类似SequenceID) 来实现。
3.12.3、弃用 QueueingCounsumer
在前面的章节中所介绍的订阅消费的方式都是通过继承DefaultConsumer 类来实现的。QueueingConsumer 在RabbitMQ 客户端3.x 版本中用得如火如荼, 但是在4.x 版本开始就被标记为@Deprecated ,想必这个类中有些无法弥补的缺陷。
QueueingConsumer consumer = new QueueingConsumer(channel);
//channel.basicQos(64);// 使用QueueingConsumer 的时候一定要添加!
channel.basicConsume(QUEUE_NAME, false, "consumer_zzh", consumer);
while (true) {QueueingConsumer.Delivery delivery = consumer.nextDelivery();String message = new String(delivery.getBody());System.out.println(" [X] Received '" + message + "''' );channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}乍一看也没什么问题,而且实际生产环境中如果不是太"傲娇" 地使用也不会造成什么大问题。QueueingConsumer 本身有几个大缺陷, 需要读者在使用时特别注意。首当其冲的就是内存溢出的问题,如果由于某些原因,队列之中堆积了比较多的消息, 就可能导致消费者客户端内存溢出假死,于是发生恶性循环,队列消息不断堆积而得不到消化。
这里使用上述代码进行一个演示,首先向一个队列发送200 多MB 的消息, 然后进行消费。在客户端调用channel . basicConsume 方法订阅队列的时候, RabbitMQ 会持续地将消息发往QueueingConsumer 中, QueueingConsumer 内部使用LinkedBlockingQueue来缓存这些消息。通过NisualVM 可以看到堆内存的变化,如图所示:

从图中可以看到堆内存一直在增加,这里只测试了发送200泌B 左右的消息, 如果发送更多的消息,那么这个堆内存会变得更大,直到出现java.lang.OutOfMemoryError 的报错。
这个内存溢出的问题可以使用Basic.Qos 来得到有效的解决, Basic.Qos 可以限制某个消费者所保持未确认消息的数量, 也就是间接地限制了QueueingConsumer 中的LinkedBlockingQueue 的大小。注意一定要在调用Basic.Consume 之前调用Basic.Qos才能生效。QueueingConsumer 还包含(但不仅限于)以下一些缺陷:
- QueueingConsumer 会拖累同一个Connection 下的所有信道,使其性能降低;
- 同步递归调用QueueingConsumer 会产生死锁:
- RabbitMQ 的自动连接恢复机制(automatic connection recove可)不支持QueueingConsumer 的这种形式
- QueueingConsumer 不是事件驱动的。