解题思路:
1.读取输入:首先读取文件总数N,然后读取每个文件的标题和内容,存储在一个Map中,其中键为文件标题,
值为文件内容的每行集合。
文件存储结构:Map<String, List<String>>
2.处理查询:读取查询总数M,然后对每个查询进行处理。将查询单词转换为小写,然后遍历每个文件,
然后再遍历每一行,检查每一行内容中是否包含全部该查询单词,如果包含则将该行加入结果列表。
结果集合存储结构:Map<String,List<String>>
结构解释:存储查询结果的列表,key为文件标题,value为该文件中包含全部查询单词的所有行
3.输出结果:对于每个查询,如果结果集合为空则输出"Not Found.",
否则输出包含查询单词的文件总数,然后按顺序输出这些文件的标题和包含全部查询单词行内容。
/*** Created by IntelliJ IDEA.* User: 加棉* Date: 2024/3/27* Time: 22:30*/
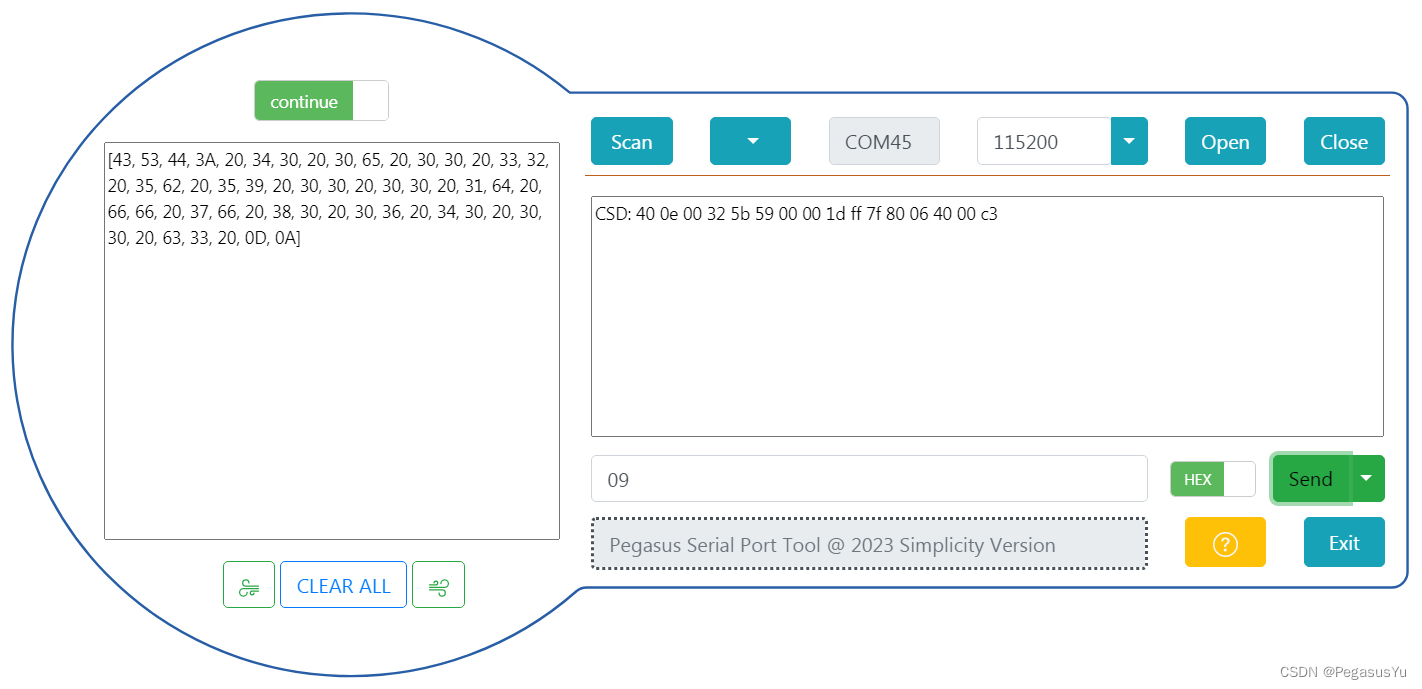
package com.yupi.springbootinit.utils;import java.util.*;public class MiniSearchEngine {public static void main(String[] args) {Scanner sc = new Scanner(System.in);int N = sc.nextInt(); // 读取文件总数sc.nextLine(); // 消耗换行符// 存储文件标题和内容的MapMap<String, List<String>> files = new HashMap<>();for (int i = 0; i < N; i++) {String title = sc.nextLine(); // 读取文件标题List<String> content = new ArrayList<>(); // 存储文件内容的行内容列表String line;while (!(line = sc.nextLine()).equals("#")) {content.add(line); // 将文件内容行加入列表}files.put(title, content); // 将文件标题和内容存入Map}int M = sc.nextInt(); // 读取查询总数sc.nextLine(); // 消耗换行符for (int i = 0; i < M; i++) {String query = sc.nextLine().toLowerCase(); // 读取并转换查询单词为小写Map<String,List<String>> results = new HashMap<>(); // 存储查询结果的列表,key为文件标题,value为该文件中包含全部查询单词的所有行for (String file : files.keySet()) {ArrayList<String> rowsIncluded = new ArrayList<>();List<String> content = files.get(file);for (String line : content) {if (line.toLowerCase().contains(query)) {results.put(file,rowsIncluded);//存放标题和该文件包含全部查询单词的行rowsIncluded.add(line); // 如果行内容包含查询单词,则将文件标题和行内容加入结果列表}}}System.out.println("##################包含\""+query+"\"这些单词的文件有:###################");if (results.isEmpty()) {System.out.println("Not Found."); // 输出未找到结果} else {System.out.println(results.size()); // 输出包含查询单词的结果总数for (String title : results.keySet()) {// 顺序输出包含查询单词的文件标题和行内容System.out.println(title);List<String> strings = results.get(title);for (String string : strings) {System.out.println(string);}}}}}
}
输入:
2
File1
This is the content of File1.
#
File2
Another file with different content.
And more content in File2.
#
3
file
content
another输出:
##################包含"file"这些单词的文件有:###################
2
File2
Another file with different content.
And more content in File2.
File1
This is the content of File1.
##################包含"content"这些单词的文件有:###################
2
File2
Another file with different content.
And more content in File2.
File1
This is the content of File1.